Opa!
Recentemente, durante um final de semana, tive a oportunidade de explorar a ferramenta Databricks. Isso foi possível através de um laboratório de cinco dias oferecido pela própria Databricks, em um curso financiado pela minha empresa atual. Além de realizar os exercícios propostos no curso, decidi utilizar o ambiente para desenvolver um projeto pessoal completo, desde a ingestão dos dados até a construção de um painel de visualização.
Todo o código do projeto está disponível nesse repositório.
Vou começar explicando o que é o Databricks, na minha visão
De forma direta, o Databricks é uma plataforma unificada de análise de dados, construída sobre o Apache Spark. Gosto de pensar nele como uma central abrangente para o ciclo de vida dos dados, uma plataforma que ajuda mais na governança do que qualquer outra coisa. É um ambiente colaborativo onde cientistas de dados, engenheiros e analistas de negócios podem trabalhar juntos em todas as etapas: desde a coleta e tratamento dos dados brutos, passando pela construção de modelos de Machine Learning, até a criação de relatórios e visualizações.
Como alguém que, apesar de não ter tanta experiência, já conseguiu experimentar a área de dados, fiquei impressionado com a quantidade de ferramentas e funcionalidades que o Databricks consegue unificar em uma única plataforma. Neste post, quero compartilhar um pouco dessa experiência, mostrando como cada etapa do meu projeto foi implementada utilizando a plataforma.
Uma observação sobre o ambiente do laboratório: O Databricks é uma plataforma robusta e, naturalmente, possui custos (altíssimos) associados. O ambiente do laboratório que utilizei, por ser focado em aprendizado, tinha algumas limitações de recursos. Por exemplo, não tive acesso às SQL Warehouses (mais orientadas para análises com SQL e ferramentas de Business Intelligence), mas pude explorar bastante os Clusters. Estes são a unidade de computação do Databricks ideal para processamento de dados em larga escala com Spark, e foram perfeitamente adequados para as necessidades do meu projeto.
A Proposta do Projeto: Uma ETL de Criptomoedas em Tempo Real
Então, qual era a proposta central do projeto? O objetivo era construir um fluxo de dados (um ETL: Extract, Transform, Load) completo. A intenção era capturar dados em tempo real, processá-los, transformá-los em informações úteis e, ao final, criar painéis (dashboards) para acompanhar os resultados.
Na prática, o projeto foi dividido em três etapas principais, todas executadas no Databricks:
- Ingestão dos Dados: Os dados foram capturados em tempo real a partir de um socket público da Binance. Esse socket fornecia o valor do índice de diversas criptomoedas em tempo real em um intervalo de 3 segundos.
- Processamento e Transformação (Camadas Bronze, Silver e Gold): Com os dados brutos em mãos (o que é comumente chamado de camada Bronze pela arquitetura Medallion), iniciei o trabalho de limpeza e estruturação. Esses dados foram transformados para uma camada intermediária, mais organizada (camada Silver), e, finalmente, agregados e preparados para análise na camada Gold, pronta para consumo. Todo esse processamento ocorreu em near-real-time.
- Visualização: Por fim, foram criados dashboards simples para o acompanhamento em tempo real de algumas criptomoedas específicas que selecionei, como Bitcoin, Ethereum e Dogecoin.
Antes de detalhar cada uma dessas etapas, considero importante mencionar como o código foi organizado e o projeto estruturado. Vamos abordar um pouco sobre…
Organização do Projeto: Integração com GitHub e CI/CD
Um dos principais desafios práticos deste laboratório era o fato de que o ambiente era reiniciado a cada 4 horas, apagando todo o meu trabalho. Para resolver isso e garantir a organização do código, a integração do Databricks com o Git (neste caso, o GitHub) foi fundamental.
Essa abordagem estende os benefícios clássicos do controle de versão para dentro do Databricks, permitindo um histórico claro de alterações, colaboração e rastreabilidade de todo o projeto.
Para automatizar o processo de restauração e atualização do meu ambiente, criei dois workflows de CI/CD utilizando o GitHub Actions.
Workflow para Sincronização de Jobs
Para os Jobs do Databricks, utilizei a API de Jobs 2.1 para criar e atualizar as definições no workspace.
- Como funciona: O diretório
jobsno meu repositório contém arquivos JSON que descrevem cada job, seguindo as regras da documentação oficial. - Gatilho: O workflow é acionado automaticamente sempre que um push é realizado neste diretório.
- Ação: Ele atualiza os jobs correspondentes no Databricks com as novas configurações, um processo que não interfere em nenhuma execução que já esteja em andamento.
Workflow para Sincronização de Notebooks
Para os notebooks, o processo foi mais direto. Utilizei a CLI (Command-Line Interface) do Databricks para fazer o upload dos arquivos do meu repositório local diretamente para o workspace.
- Como funciona: No Databricks, um notebook é essencialmente um arquivo fonte (com extensão
.py,.sql, etc.). Uma característica interessante é que, mesmo em um notebook Python, por exemplo, é possível executar células em outras linguagens usando comandos mágicos, como%sqlou%md(para Markdown), no início da célula. - Ação: O workflow envia cada arquivo do diretório
notebooksdo repositório para o local correspondente no workspace do Databricks. Para que o upload via CLI funcione corretamente, é necessário especificar a linguagem padrão do notebook no comando de envio.
Os diretórios mencionados possuem os seguintes arquivos:
Etapa 1: Ingestão em Tempo Real para a Camada Bronze
Com o projeto organizado, a primeira etapa técnica foi a ingestão: o processo de capturar os dados brutos da fonte e salvá-los na plataforma. O objetivo aqui é simples: trazer os dados para dentro do nosso ambiente da forma mais fiel e confiável possível, criando a nossa Camada Bronze.
Para este projeto, a fonte de dados era um WebSocket da Binance, que transmite em tempo real cada negócio agregado do par de moedas Bitcoin/Tether (BTCUSDT).
A Abordagem: Lendo o Stream com Python e Spark
O processo foi implementado em um notebook Databricks utilizando Python. Vamos ver os passos principais:
Conexão e Estrutura (Schema):
O primeiro passo foi estabelecer a conexão com o WebSocket da Binance. Antes mesmo de receber os dados, defini um schema rígido com o
StructTypedo PySpark. Isso é uma boa prática fundamental na engenharia de dados, pois garante que os dados que salvamos tenham sempre a estrutura e os tipos corretos (texto, número, data/hora), prevenindo erros e inconsistências no futuro. Além dos campos originais da fonte, adicionei alguns campos de metadados:received_timestamp: A data e hora exatas em que o nosso processo recebeu o dado.interval_partition: A data e hora da coleta, que será usada mais tarde para uma otimização da tabela.
schema = StructType([ StructField("event_type", StringType(), True), StructField("event_timestamp", TimestampType(), True), StructField("symbol", StringType(), True), StructField("mark_price", StringType(), True), StructField("index_price", StringType(), True), StructField("estimated_settle_price", StringType(), True), StructField("funding_rate", StringType(), True), StructField("next_funding_timestamp", TimestampType(), True), StructField("received_timestamp", TimestampType(), True), StructField("interval_partition", TimestampType(), True), ])Processamento em Micro-lotes (Micro-batches):
Receber dados de um stream significa um fluxo constante de informações, uma por uma. Gravar cada registro individualmente no disco seria extremamente ineficiente e criaria um problema conhecido como “small files” (muitos arquivos pequenos), que degrada a performance de sistemas distribuídos como o Spark.
Para resolver isso, implementei uma lógica de buffer. O código coleta os registros em uma lista na memória e, somente quando atinge um tamanho pré-definido (um lote de 100 registros), ele converte essa lista em um DataFrame Spark e o salva de uma vez. Essa abordagem de micro-lotes é muito mais eficiente.
BATCH_SIZE = 10_000 # Esse tamanho de lote faz com que as inserções na bronze aconteçam a cada 3 minutos, aproximadamente async with websockets.connect(url) as ws: buffer = [] while True: data = await ws.recv() # Recebe uma iteração do stream da binance parsed_array = json.loads(data) for item in parsed_array: row = parse_data(item) # Formata os dados para o schema definido buffer.append(row) if len(buffer) >= BATCH_SIZE: df = spark.createDataFrame(buffer, schema=schema) df.write.format("delta") \ .mode("append") \ .partitionBy("interval_partition") \ .saveAsTable("bronze_binance_mark_price") buffer = [] print(f"{datetime.now(pytz.utc).strftime('%Y-%m-%d %H:%M:%S')} Batch saved with {BATCH_SIZE} records")Salvando na Tabela Bronze com Delta Lake:
Este é o ponto central da etapa de ingestão. O lote de dados não foi salvo em um arquivo CSV, JSON ou Parquet qualquer, mas sim em uma tabela no formato Delta Lake.
O Delta Lake é uma camada de armazenamento (de código aberto :D) que traz confiabilidade e performance aos data lakes. Na prática, ele adiciona funcionalidades de um banco de dados transacional (como transações ACID) sobre os arquivos do nosso data lake. Ao usar
.format("delta"), garantimos que cada escrita ou é concluída com sucesso, ou falha sem deixar dados corrompidos.Além disso, ao salvar, utilizei
.partitionBy("interval_partition"). Isso instrui o Databricks a organizar fisicamente os dados em pastas separadas por data e hora (sem minutos, segundos e microsegundos). Esse particionamento é uma técnica de otimização que torna as consultas filtradas por data (por exemplo, “analisar todos os dados de ontem às 23h”) drasticamente mais rápidas.
Ao final deste processo, tínhamos uma tabela chamada bronze_binance_mark_price sendo alimentada continuamente. Essa tabela representa a nossa “fonte única da verdade” para os dados brutos, pronta para ser consumida pela próxima etapa: a limpeza e transformação para a Camada Silver.
Também é importante mencionar que, para garantir a continuidade do processo, o notebook foi configurado como um Job no Databricks. Normalmente, isso significaria que ele seria executado automaticamente em intervalos regulares, mas nesse caso, onde precisamos manter o Stream ligado à fonte, o Job foi configurado para rodar continuamente. Uma configuração foi criada em jobs/binance_mark_prices_ingestion.json, um job com uma task:
{
"name": "Binance Mark Prices Ingestion",
"existing_cluster_id": "0527-020929-w1o58jct",
"notebook_task": {
"notebook_path": "/Shared/Git/bronze_binance_mark_price_stream_ingestion.py"
},
"max_retries": 1,
"timeout_seconds": 0,
"max_concurrent_runs": 1
}
E que pode ser visualizado pela interface do Databricks, como no seguinte exemplo:
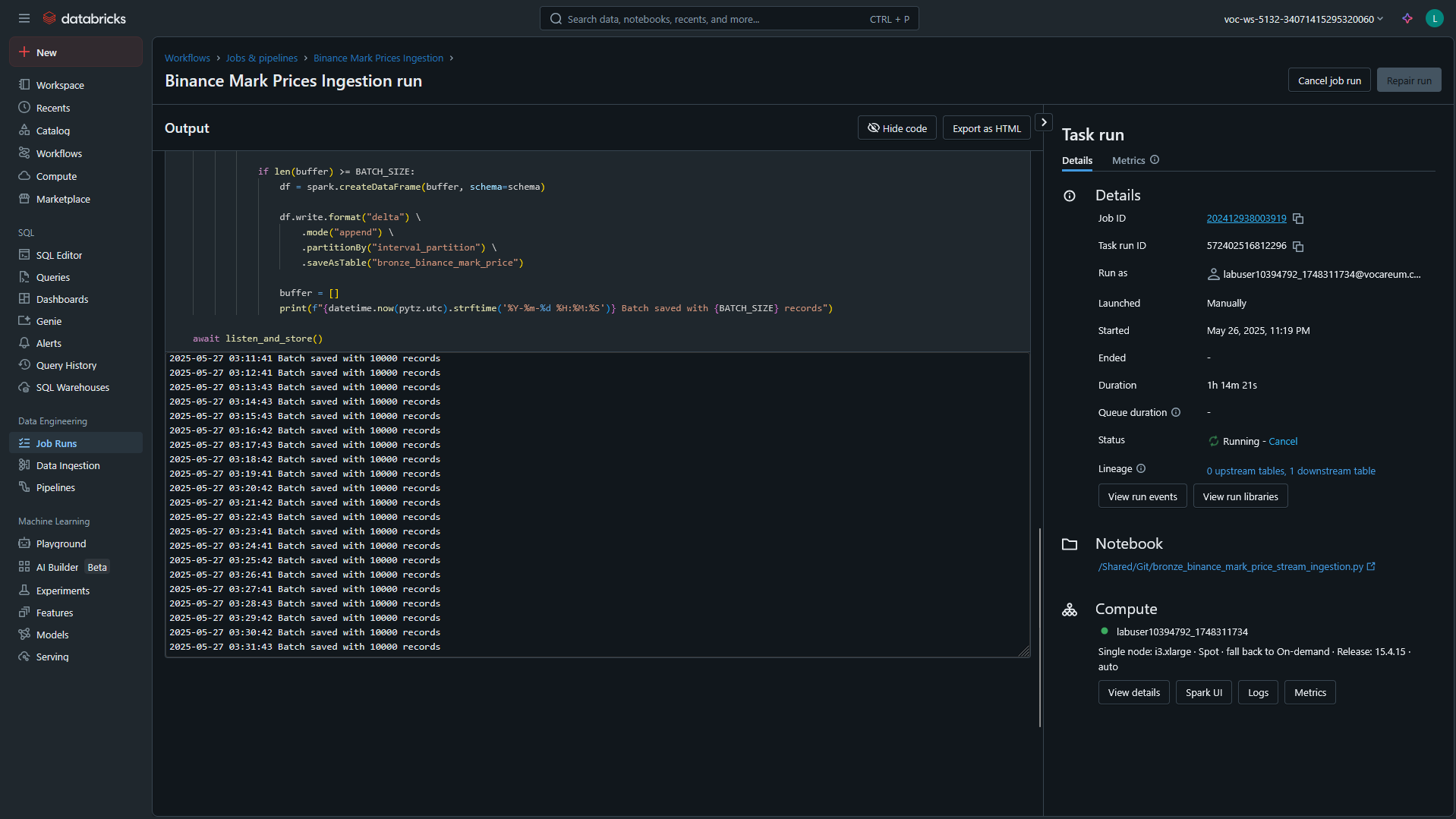
Se reparar bem, vai perceber que o job está rodando há mais de 1 horas, o que significa que ele está ativo e recebendo dados continuamente.
Etapa 2: Refinando os Dados com as Camadas Silver e Gold
Com os dados brutos chegando continuamente na nossa camada Bronze, o próximo passo é transformá-los em algo realmente útil. É aqui que entram as camadas Silver (Prata) e Gold (Ouro) da nossa arquitetura. A meta é simples:
- Silver: Limpar, filtrar e agregar os dados brutos.
- Gold: Enriquecer e modelar os dados para responder a perguntas de negócio específicas, deixando-os prontos para análise e visualização.
Orquestrando o Fluxo com Databricks Jobs
Todo esse processo de transformação não é manual. Eu o automatizei usando mais um Job, que, dessa vez, é uma forma de agendar e executar notebooks ou scripts de forma recorrente. O Job foi definido em um arquivo JSON e configurado para rodar a cada 5 minutos, mantendo nossos dados sempre atualizados.
O mais importante é que o Job define uma dependência: a tarefa da camada Gold só começa depois que a tarefa da Silver é concluída com sucesso. Isso garante a integridade e a consistência do nosso fluxo de dados.
{
"tasks": [
{ "task_key": "Silver", "..." },
{
"task_key": "Gold_By_Symbol",
// Define a dependência da tarefa Silver
"depends_on": [
{ "task_key": "Silver" }
],
"..."
}
],
"schedule": {
"quartz_cron_expression": "0 0/5 * ? * *",
"timezone_id": "America/Sao_Paulo"
}
}
É muito interessante observar na interface do Databricks como os Jobs são executados em sequência, pois é uma visualização MUITO parecida com o que vemos em ferramentas de orquestração de workflows, como o Apache Airflow. Isso facilita muito a compreensão do fluxo de dados e a depuração de problemas.
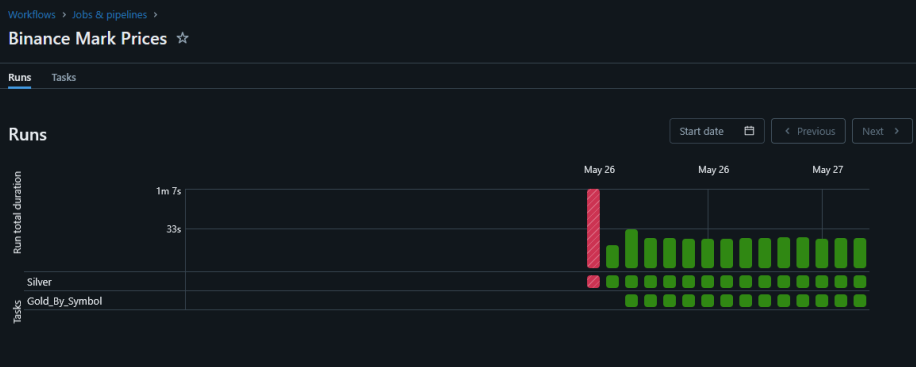
Da Bronze para a Silver: Limpeza e Agregação
A primeira transformação pega os dados brutos da tabela Bronze e os refina. O script SQL para esta etapa realiza duas tarefas principais:
- Agregação por Minuto: Os dados chegam várias vezes por segundo. Para uma análise mais clara, eu os agrupei para ter o preço médio por minuto de cada criptomoeda.
- Operação MERGE: Em vez de apagar e inserir dados, utilizei o comando MERGE. Ele é uma espécie de “upsert” inteligente: se um registro para um determinado minuto e símbolo já existe, ele o atualiza; se não existe, ele o insere. Isso torna a operação eficiente e idempotente (pode ser executada várias vezes sem gerar duplicatas).
-- Simplificação da query principal da camada Silver
MERGE INTO silver_binance_mark_price AS T
USING (
SELECT
date_trunc('MINUTE', event_timestamp) AS `date`,
date_trunc('HOUR', event_timestamp) AS partition_interval,
symbol,
avg(cast(index_price AS DECIMAL(23, 8))) AS index_price -- Agrega o preço por minuto
FROM
bronze_binance_mark_price
WHERE
received_timestamp >= now() - INTERVAL 10 MINUTE -- Processa apenas dados recentes, já que roda a cada 5 minutos
GROUP BY ALL
) AS S
ON T.`date` = S.`date` AND T.symbol = S.symbol AND T.partition_interval = S.partition_interval
WHEN MATCHED THEN UPDATE SET ...
WHEN NOT MATCHED THEN INSERT ...
Da Silver para a Gold: Preenchendo Lacunas para Análise
A camada Gold é onde preparamos os dados para o consumo final. Um problema comum em dados de streaming é que podem existir lacunas. Por exemplo, uma moeda menos popular pode não ter tido negociações em um determinado minuto. Um gráfico com buracos não é ideal.
O objetivo da query da camada Gold é justamente resolver isso. A lógica é um pouco mais complexa:
- Criação de um “Gabarito”: Primeiro, o script cria uma grade perfeita com todos os minutos dos últimos instantes e cruza essa informação com todos os símbolos de moedas existentes.
- Preenchimento de Lacunas: Em seguida, ele utiliza uma função de janela (LAST(…, TRUE) OVER (…)) para preencher os minutos em que não houve negociação para uma moeda, repetindo o último preço válido conhecido para ela.
O resultado é uma tabela gold limpa, completa e sem falhas na série temporal, perfeita para ser usada em dashboards.
A query SQL que faz toda essa implementação é bem extensa e tem 6 diferentes CTEs, mas caso esteja interessado, a mesma pode ser acessada aqui.
Etapa 3: Visualizando os Resultados
Com os dados na camada Gold, o trabalho pesado de engenharia de dados está concluído. A etapa final é a mais simples gratificante: visualizar os resultados.
A tabela Gold, com seus dados limpos e sem lacunas, serve como a fonte de dados perfeita para os gráficos. Utilizando as ferramentas nativas de visualização do Databricks, pude criar um notebook com uma dashboard embarcada, a alternativa que eu tive nesse lab onde apenas clusters (e não warehouses) estavam disponívels.
Criei gráficos de linha para acompanhar a flutuação do preço de 4 das principais moedas (Bitcoin, Ethereum, etc.) ao longo do tempo. Ver a atualização dos gráficos ao longo do tempo foi a prova final de que nosso pipeline de dados de ponta a ponta estava funcionando perfeitamente, transformando dados brutos de um stream em insights visuais e acionáveis.
Segue um exemplo de como ficou esse protótipo de dashboard:
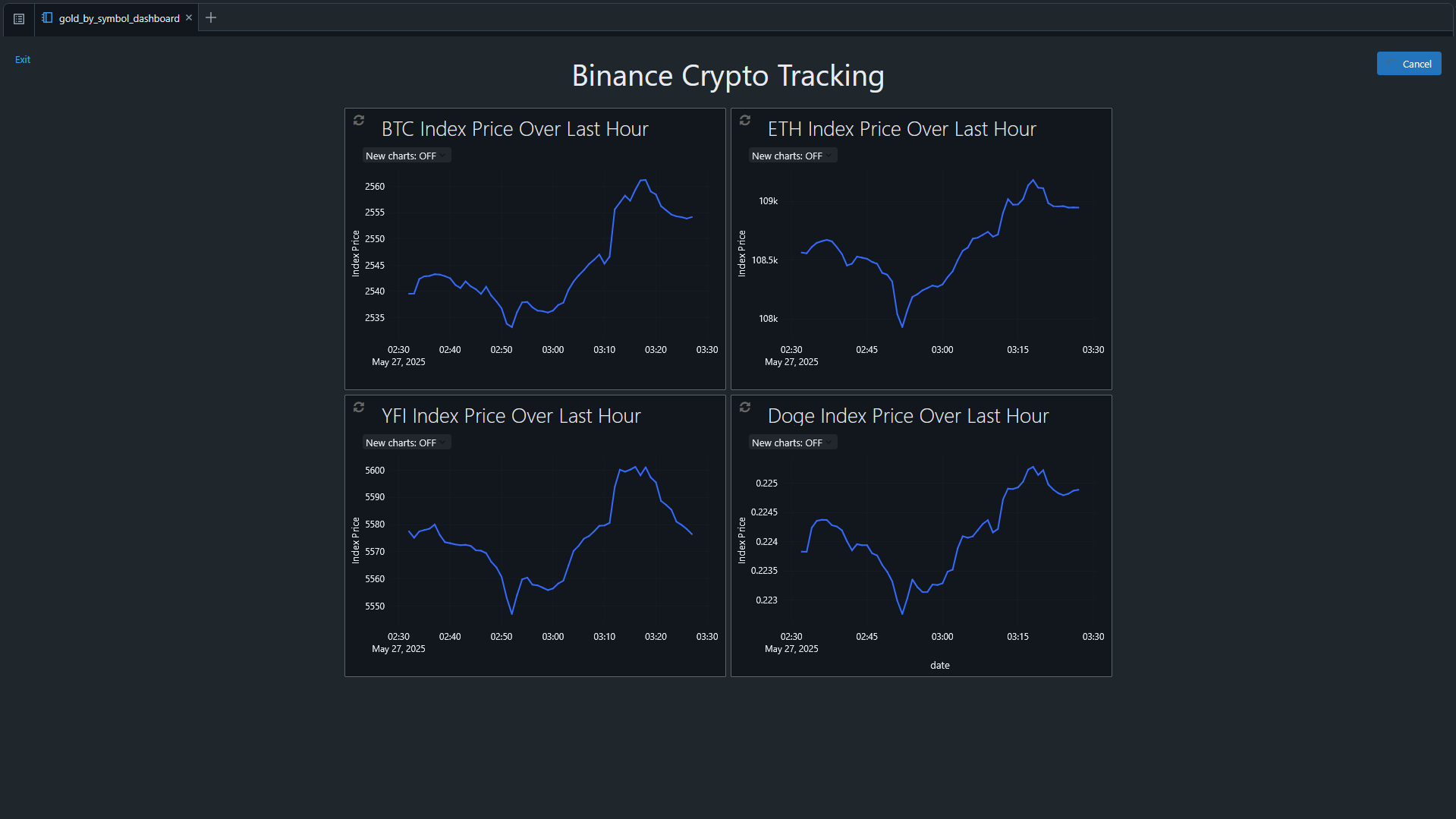
Cada um desses gráficos é alimentado diretamente pela tabela Gold, que é atualizada a cada 5 minutos. Isso significa que, sempre que um novo lote de dados é processado, os gráficos refletem imediatamente os últimos 60 minutos disponíveis.
A criação de dashboards no Databricks é bastante intuitiva. Ela se assemelha a outras ferramentas de visualização, como o Tableau ou o Power BI, mas com a vantagem de estar totalmente integrada ao ambiente de dados. Isso permite que cientistas de dados e engenheiros criem visualizações diretamente a partir dos notebooks, sem precisar exportar os dados para fora da plataforma.
Com base em experiências pessoais (meu próprio uso e conversas com colaboradores), as dashboards do Databricks ainda parecem um pouco mais limitadas em comparação com ferramentas dedicadas de BI, como o Tableau. No entanto, vale lembrar que a plataforma Databricks está em constante evolução, e novas funcionalidades são frequentemente adicionadas. Além disso, a integração com outras ferramentas de visualização é sempre uma opção.
Explorar o Databricks foi uma experiência muito interessante. A plataforma realmente brilha quando se trata de unificar o ciclo de vida dos dados, desde a ingestão até a visualização. A capacidade de trabalhar com grandes volumes de dados em tempo real, combinada com a facilidade de uso e as ferramentas colaborativas, torna o Databricks uma grande escolha para projetos de ciência de dados e engenharia. Já fazia um tempo que eu queria explorar mais a fundo essa plataforma, e essa oportunidade de laboratório foi perfeita para isso.
Obrigado por ler até aqui! Espero que este post tenha agregado tanto valor para você quanto agregou para mim. Se você tiver alguma dúvida ou quiser discutir mais sobre o assunto, fique à vontade para entrar em contato!